
How OpenAI’s GPT Models Work – A Beginner’s Guide
Generative AI has been making huge waves in technology, and OpenAI’s GPT models are at the heart of this revolution. But how exactly do these powerful models work? In this beginner-friendly guide, we’ll break down the architecture of GPT, explain essential concepts like language modeling, training datasets, and fine-tuning — all in simple terms.
🔍 What is GPT?
GPT stands for Generative Pre-trained Transformer.
It’s a type of advanced AI model built to understand and generate human-like text. GPT models belong to a family of transformer-based neural networks that excel at natural language processing (NLP) tasks such as text generation, translation, summarization, and even conversational agents like chatbots.
🧱 The Architecture: Transformer Model Simplified
At the core of GPT lies the Transformer Architecture, introduced in 2017 by Vaswani et al. The main advantage of transformers is their ability to handle long-range dependencies in text using a mechanism called self-attention.
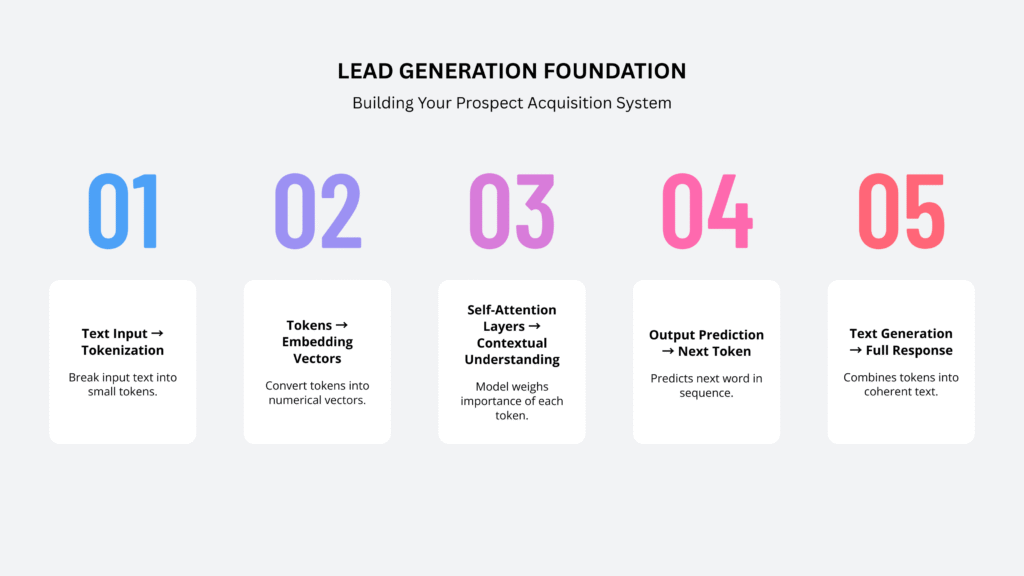
How does it work?
- The input text is first tokenized — broken into small units like words or subwords.
- Each token is transformed into a vector (a set of numbers representing its meaning).
- The model processes all tokens in parallel using self-attention layers that let the model weigh the importance of every token relative to others.
- Multiple layers of these attention and feed-forward neural network blocks are stacked to improve learning capacity.
This enables GPT to understand the context and relationships between words, allowing it to generate coherent and meaningful sentences.
📚 Language Modeling: The Heart of GPT
GPT is trained as a language model, meaning it learns to predict the next word in a sentence based on the words that came before.
For example, given the input:
“The sun rises in the”
The model predicts the next word — likely “east”.
This training process helps GPT understand grammar, facts, reasoning, and even some creative tasks by learning patterns in the text data.
🏋️♂️ Training Dataset: Learning from Huge Text Corpora
GPT models are trained on vast datasets containing text from books, articles, websites, and more.
For instance, OpenAI’s GPT-3 was trained on hundreds of gigabytes of text data from diverse sources to develop a deep understanding of language.
The model doesn’t memorize facts but rather learns patterns and statistical relationships between words. This makes it highly flexible in generating original and contextually relevant content.
🔧 Fine-Tuning: Customizing GPT for Specific Tasks
After pre-training on general text, GPT models can be fine-tuned for specific use cases. Fine-tuning involves additional training using a smaller, domain-specific dataset to specialize the model.
Example:
- Fine-tuning GPT to act as a customer support chatbot by training it on company FAQs and conversation logs.
This makes the model more accurate and useful in real-world applications without needing to train from scratch.
📊 Visual Overview of GPT Workflow
🚀 Why Should You Care?
Understanding how GPT works helps you build smarter applications — from content generation tools to intelligent chatbots. Instead of relying on manual coding, you can now integrate powerful AI models via APIs and customize them to solve real problems.
👉 Get Hands-On Experience in Our Workshop!
Curious to experience how GPT models work in practice?
Join our “Building with Generative AI: A Beginner’s Workshop” happening on
🗓️ 20–21 September 2025
⏰ 12 hours of intensive, practical learning
🎯 Learn how to integrate OpenAI’s GPT API into your own applications, build an AI chatbot, and understand ethical usage.
👉 Enroll Now and Build Your First AI Chatbot!
Generative AI isn’t just the future — it’s the present. Start your journey today by learning the foundational concepts that power intelligent applications.