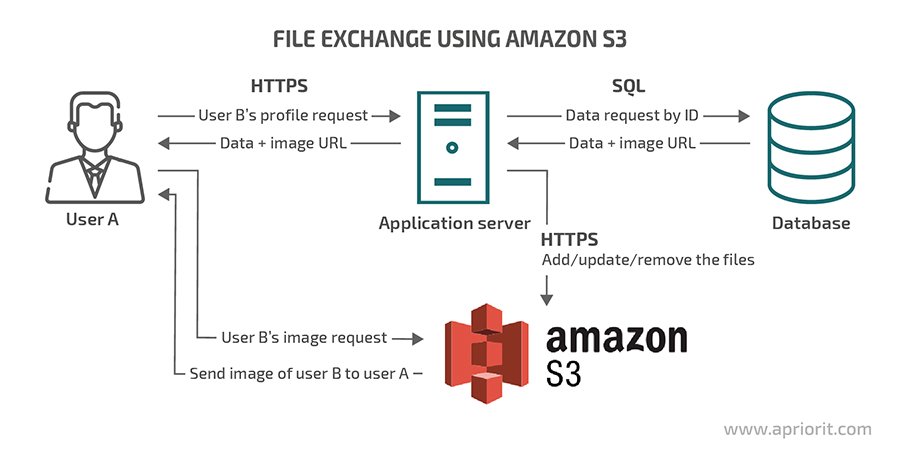
In modern backend development, storing and retrieving files efficiently is a critical requirement for many applications. Whether it’s user-generated content, media files, or documents, cloud storage solutions like Amazon S3 (Simple Storage Service) provide a scalable, secure, and cost-effective way to manage files. In this blog, we’ll explore how to store and retrieve files in AWS S3, covering setup, integration, and best practices.
Why Use AWS S3 for File Storage?
Amazon S3 is one of the most popular cloud storage services, offering several advantages:
- Scalability: S3 can handle virtually unlimited storage and high request rates.
- Durability: S3 provides 99.999999999% (11 nines) durability for stored objects.
- Security: S3 supports encryption, access control, and compliance with industry standards.
- Cost-Effectiveness: Pay only for the storage and requests you use, with no upfront costs.
- Integration: S3 integrates seamlessly with other AWS services and third-party tools.
Setting Up AWS S3
Before you can store and retrieve files in S3, you need to set up an S3 bucket and configure access permissions.
Step 1: Create an S3 Bucket
- Log in to the AWS Management Console.
- Navigate to the S3 service.
- Click Create bucket.
- Enter a unique bucket name (e.g.,
my-file-storage-bucket). - Choose a region (e.g.,
us-east-1). - Configure additional settings (e.g., versioning, logging) as needed.
- Click Create bucket.
Step 2: Configure Access Permissions
- Go to the Permissions tab of your bucket.
- Under Block public access, ensure that public access is blocked unless required.
- Under Bucket Policy, add a policy to grant access to specific users or roles.
- Example policy to allow read/write access:jsonCopy{ “Version”: “2012-10-17”, “Statement”: [ { “Effect”: “Allow”, “Principal”: “*”, “Action”: [“s3:GetObject”, “s3:PutObject”], “Resource”: “arn:aws:s3:::my-file-storage-bucket/*” } ] }
Step 3: Create IAM User and Access Keys
- Navigate to the IAM service.
- Create a new user (e.g.,
s3-file-uploader). - Attach a policy to grant S3 access (e.g.,
AmazonS3FullAccess). - Generate access keys (Access Key ID and Secret Access Key) for programmatic access.
Integrating AWS S3 with Your Backend
To interact with S3 from your backend application, you’ll need to use the AWS SDK. Below, we’ll demonstrate how to store and retrieve files in S3 using Node.js.
Step 1: Install the AWS SDK
Install the AWS SDK for Node.js:
bash
Copy
npm install aws-sdk
Step 2: Configure the AWS SDK
Create a file called s3.js and configure the AWS SDK with your credentials:
javascript
Copy
const AWS = require('aws-sdk');
// Configure AWS SDK
AWS.config.update({
accessKeyId: 'YOUR_ACCESS_KEY_ID',
secretAccessKey: 'YOUR_SECRET_ACCESS_KEY',
region: 'us-east-1',
});
const s3 = new AWS.S3();
Step 3: Upload a File to S3
Add a function to upload a file to S3:
javascript
Copy
async function uploadFile(fileName, fileContent) {
const params = {
Bucket: 'my-file-storage-bucket',
Key: fileName, // File name in S3
Body: fileContent, // File content
};
try {
const data = await s3.upload(params).promise();
console.log('File uploaded successfully:', data.Location);
return data.Location; // Returns the file URL
} catch (err) {
console.error('Error uploading file:', err);
throw err;
}
}
// Example usage
uploadFile('example.txt', 'Hello, S3!');
Step 4: Retrieve a File from S3
Add a function to retrieve a file from S3:
javascript
Copy
async function getFile(fileName) {
const params = {
Bucket: 'my-file-storage-bucket',
Key: fileName, // File name in S3
};
try {
const data = await s3.getObject(params).promise();
console.log('File retrieved successfully:', data.Body.toString());
return data.Body.toString(); // Returns the file content
} catch (err) {
console.error('Error retrieving file:', err);
throw err;
}
}
// Example usage
getFile('example.txt');
Step 5: Delete a File from S3
Add a function to delete a file from S3:
javascript
Copy
async function deleteFile(fileName) {
const params = {
Bucket: 'my-file-storage-bucket',
Key: fileName, // File name in S3
};
try {
const data = await s3.deleteObject(params).promise();
console.log('File deleted successfully:', data);
return data;
} catch (err) {
console.error('Error deleting file:', err);
throw err;
}
}
// Example usage
deleteFile('example.txt');
Best Practices for Using AWS S3
- Use IAM Roles for EC2 Instances: Instead of hardcoding credentials, use IAM roles for EC2 instances to securely access S3.
- Enable Versioning: Turn on versioning to protect against accidental deletions or overwrites.
- Use Lifecycle Policies: Automate the transition of files to cheaper storage classes (e.g., S3 Glacier) or delete old files.
- Encrypt Data: Enable server-side encryption (SSE) to protect your data at rest.
- Optimize Performance: Use multipart uploads for large files and enable transfer acceleration for faster uploads.
- Monitor Usage: Use AWS CloudWatch and S3 Access Logs to monitor and analyze usage patterns.
- Secure Access: Use bucket policies and IAM policies to restrict access to authorized users and applications.
Real-World Example: Netflix
Netflix uses AWS S3 to store and manage media files for its streaming platform. By leveraging S3’s scalability and durability, Netflix can:
- Store petabytes of video content.
- Deliver content to millions of users worldwide.
- Ensure high availability and fault tolerance.
Conclusion
AWS S3 is a powerful and versatile solution for storing and retrieving files in backend development. By following the steps and best practices outlined in this blog, you can integrate S3 into your application and take advantage of its scalability, security, and cost-effectiveness.